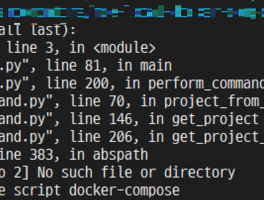
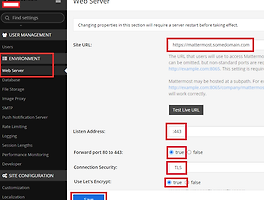
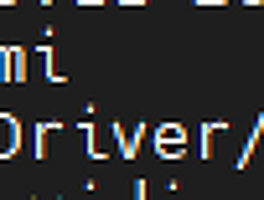
공부 (316) 썸네일형 리스트형 [책읽기] Tucker의 Go 언어 프로그래밍 - 공봉식, 골든래빗 ( 를 빙자한 Golang Cheat Sheet ㅋ ) 책 읽은것 정리, 그리고 Cheat Sheet 용으로 ChatGPT랑 공부를 좀 했음 제목 : Tucker의 Go 언어 프로그래밍 - 공봉식, 골든래빗 책을 읽기전 Go라는 언어가 예전부터 나왔지만, 잠시 공부했다가 그냥 그런가 보다 했다. 한창 Docker와 Kubernetes를 관련 업무를 진행할 때 이 쪽 관련 주 언어는 Go 인걸을 알게 되었다. 그래서 관심을 가지고 있다 읽게 된 책이다. 나의 주 언어가 Java이긴 하지만, Spring이 좋고 말고를 떠나서 다른 언어들에 비해서 메모리도 많이 사용하고, 메모리 관리가 어렵다는게 큰 문제 라는것을 최근에 격고 있다.메모리 관리는 GC 가 알아서 해 주니 뭐가 문제냐고 생각할 수도 있지만, 내가 말하는 메모리 관리 문제는 Memory Leak 이나.. [책읽기] Kubernetes Best Practices 쿠버테니스 모범 사례 - 오라일리, 한빛미디어 근황먼저. 2년전쯤부터 한컴싸인(https://www.hancomsign.com)이라는 웹서비스를 개발하다, 그 조직이 직무별로 쪼개지면서 개발팀장을 하다, 최근 더 흥미로운, 혹은 변화가 많은? 조직으로 이동하여 현재는 팀원을 하고 있다. 그전 AI를 하던때부터 지금까지 많은 책들을 읽었는데, 정리할 시간이 없어 오랜만에 일찍 퇴근한 김에 읽었던 책들중 몇권을 순차적으로 정리해 본다. 오래전에 읽었던 책들도 있어서, 지금 이 글을 읽는 사람에게는 이미 오래된 책일 수 있이라 도움이 될런지 모르겠지만, 그래도 읽은 티라도 내 보려고 대충 정리해 본다. 그러니 걍 그런가 보다 하자. 제목 : Kubernetes Best Practices 쿠버테니스 모범 사례 - 오라일리, 한빛미디어 책 읽기 이 책은 초보.. WSL2에서 docker-compose 사용시 FileNotFoundError: [Errno 2] No such file or directory 에러 발생시 문제 해결 백만년만에 블로그 글을 쓴다. 제작년 중순까지 AI쪽을 하다가, 이제는 웹서비스를 개발(이라기 보다는 관리??) 하고 있다. 우선 이 문제가 발생되는 상황은 아래와 같다. 1. Windows 10에서 IntelliJ를 이용해서 c:\works 디렉토리에 있는 코드를 건들고 있음. 2. docker-compos.yml 파일은 c:\works 에 있음 3. WSL2에서 /mnt/c/works 하위 디렉토리로 이동 후 docker-compose up 등을 수행하고 있음. docker-compose 가 실행되고 있는 상태에서 Ctrl + C 등을 눌러 강제로 죽이뒤에 다시 docker-compose 를 실행시키면 아래처럼 에러가 나는경우가 있다. chan@DESKTOP-OQG0APE:~/xxxxxxxxxxxxx.. docker로 Mattermost 설치시 let's encrypt 이용해 tls 적용하는 방법 slack을 쓰다가... 팀에서 Slack을 잘 사용하고 있었다. 어느날 무료로 높은 등급을 준다고 해서 잘 썼는데... 시간이 지났더니.. 그게 끝났다. 아, 이제 검색이 안되네? ㅎ. 유료로 사용하긴 비싸고... 역시 설치형인가.. 흠.. Rocket.chat/Mattermost 를 대충 써 보니.. Rocket.chat 과 Mattermost가 설치형으로 사용할 수 있다. 둘 다 설치해 봤는데, Rocket.chat이 사용이 좀 더 불편해서 Mattermost 를 설치하는것으로 결정. Mattermost 설치하기 역시나 docker로 설치하면 편하다. 멀티노드로 실행하려면 다음의 링크를 타고 가자 : https://docs.mattermost.com/install/prod-docker.html 나는.. NVIDIA GPU에서 nvidia-smi 명령시 NVML: Driver/library version mismatch 발생 원인은 아마도? Kubernetes의 Node에 GPU Pod가 뜰 때, 문제가 계속 발생하네? GPU를 사용하는 Pod가 떠 있을때는 문제가 안 됐는데, 가끔씩 새로 띄울때 Pod가 안 뜨는 문제가 있었다. 주로 이런 경우 nvidia-smi 명령을 치면 아래와 같은 에러 메세지가 떴었다. Failed to initialize NVML: Driver/library version mismatch 단순히 에러 메세지로만 보면, 드라이버와 라이브러리가 매치 되지 않는다는건데, 난 서버에 아무런 짓도 안 해 줬는데도 에러가 생기는 것이다. 약 1년전부터 가끔 발생한 문제였는데, 이것저것 찾아 보았지만, 다들 재부팅하면 해결 될 거라는 이야기만... stackoverflow.com/questions/43022843/nvidia.. [PyTorch] x86 CPU에서 양자화(Quantization) 관련 실행시 에러가 나는 경우 - Didn't find engine for operation quantized::conv_prepack NoQEngine 문제 상황 발생 Kubernetes에서 AI 엔진을 돌리는데, GPU로 사용할때는 문제가 없었는데... CPU를 사용하도록 해서 동작시키니 동작하지 않는 문제가 발생 에러 메세지 아래와 비슷한 문제가 발생하면서 동작하지 않는 문제가 있었다. Didn't find engine for operation quantized::conv_prepack NoQEngine conv_prepack뿐만 아니라, linear_prepack 라는 에러가 발생하기도 한다. 알고 봤더니, CPU를 사용할 때는 Quantization 과정에서 문제가 발생한것이었다. 분석하기 소스에서 에러 메세지 찾기 해당 에러를 출력하는 코드를 찾아보면 아래와 같다. 관련링크 : qconv_prepack.cpp 위 그림에서 코드의 제일 윗부분부터.. [PyTorch] 1.8 release와 함께 GPU memory fraction 이 지원됩니다. - torch.cuda.set_per_process_memory_fraction 인공지능할때 GPU 메모리를 나눠쓰고 싶어요. AI 서비스를 운영하려고 하면, GPU 메모리를 나눠써야 하는 경우가 있다. 관련링크 : [kubernetes] Extended Resource로 나만의 리소스 제약 (request, limit) 만들어서 사용하기 - GPU RAM 나눠쓰기 예전글에 적었다시피, 운영하는 장비의 GPU memory이 너무 큰데 한놈이 다 쓴다거나, 혹은 한 놈이 비정상적 동작으로 인해서 GPU memory를 너무 많이 쓴다면 다른 애들에 문제가 생길거다. Tensorflow 에서는 나눠쓰는것을 옛날부터 지원했다. tensorflow에서는 1.x 대 부터 per_process_gpu_memory_fraction 를 사용해서 process당 사용할 수 있는 GPU 메모리를 지정할.. [Vultr] VPS Instance Type 별 CPU 속도 확인 Vultr 전에도 이야기 했지만, 난 Vultr을 사용하고 있다. 관련링크 : https://blog.ggaman.com/1019 VPC Instance에서 CPU는 어떤것을 사용할까? Vultr는 4가지 Type의 Instance를 지원해 준다. ( Cloud Compute, High Frequency, Bare Metal, Dedicated Cloud ) 당연히 High Frequency는 Cloud Compute보다는 빠르겠지... 하지만 얼마나 빠른지, 혹은 Cloud Compute에서 충분한 속도가 난다면 굳이 더 비싼 제품을 고를 필요가 있을까? 그래서 각 제품의 /proc/cpuinfo 정보를 확인해 보았다. Cloud Compute 한국 리전에서 만들수 있어서, 1vCPU, 1GByte R.. 이전 1 2 3 4 ··· 40 다음