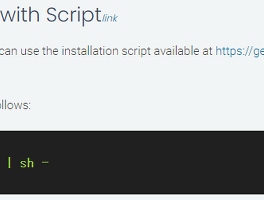
공부/컴퓨터 (284) 썸네일형 리스트형 [kubernetes] Extended Resource로 나만의 리소스 제약 (request, limit) 만들어서 사용하기 - GPU RAM 나눠쓰기 여기서 말하는 Resource는 "CRD(Custom Resource Definition)"의 Resource가 아니라, 정말 "자원"개념의 "Resource"다. GPU는 왜 나눠쓸 수 없을까? 나는 NVIDIA RTX 8000 GPU를 Node에 1개 달아둔 환경에서 작업중이다. NVIDIA RTX 8000은 Datacenter에서 사용할 수 있도록 허용된 NVIDIA 드라이버 라이선스가 있으며, 무려 VRAM이 48GB 나 된다!!! Kubernetes에는 리소스 쿼터라는 개념이 있어서, CPU, RAM을 나눠서 사용할 수 있도록 기능을 제공해 준다. 관련링크 : kubernetes.io/docs/concepts/configuration/manage-resources-containers/ 예를들어,.. [Kubernetes] k3s 1.20이하에서 Traefik 1.81 제거하고 Traefik 2.x 설치하기 2021년 5월 업데이트... k3s가 1.21부터는 Traefik v1이 설치되어 있지 않다면, Traefik v2를 기본으로 설치 한다고 합니다. 그러니 최신 버젼을 사용하는 사람은 아래 내용은 그냥 참고삼아 읽으시면 됩니다. k3s가 좋긴한데... Traefik 이 문제라... k3s를 이용하면 단한줄의 명령어만으로 single node kubernetes를 구성할 수 있다. 관련 링크 1 : https://blog.ggaman.com/1018?category=332239 관련 링크 2 : https://rancher.com/docs/k3s/latest/en/installation/install-options/ curl -sfL https://get.k3s.io | sh - 단, 한줄로 무언가를 할.. [python] Flask로 app.run() 실행시 두개의 Process가 뜨는 문제 오늘도 트러블슈팅 문제 상황 AI 엔진을 띄우면 GPU를 사용하는 Process가 2개가 뜨면서 GPU RAM을 쓸데 없이 두번 먹는 현상. 문제 분석 웹 서버를 띄울때 Flask를 활용하고 있음 "main" 에서 model을 로딩하면 최초 실행된 python process가 GPU 메모리를 1.5GB 정도 사용 이후 Flask의 app.run 을 실행. Flask의 app.run을 실행하면 python process가 1개 더 뜨면서 GPU 메모리를 1.5GB 정도 사용 아마도 app.run 실행시 python process 가 fork() 되면서 GPU메모리까지 clone 되는것으로 예측?? 문제 확인 main부분에서 바로 model을 로딩하지 않고, 바로 Flask의 app.run을 실행 최초 pr.. [Kubernetes] k3s에서 컨테이너를 띄웠는데 왜 GPU를 못 쓰지? k3s에서 GPU를 왜 못쓰지? docker를 설치하고, nvidiai-docker를 설치하고, k3s를 설치 했다. docker를 이용해서 GPU를 사용하는 컨테이너를 띄웠을때는 GPU를 잘 사용하는데... kubernetes에서 Pod를 띄우니 GPU를 못 사용하네? 왜 그럴까? 미리 정리하면... 조건 : docker 설치. nvidia-docker 설치. k3s 설치 문제 : Kubernetes에서 띄운 Pod에서 GPU를 사용하지 못함. 해결 : k3s를 설치하면 기본적으로 containerd 를 사용하게 되어 있음. nvidia-docker를 써야만 GPU를 활용할 수 있음. 즉, k3s의 container runtime을 docker로 변경해야 함. k3s 설치시 --docker 옵션 추가 .. [kubernetes] node에 달린 NVIDIA GPU를 Pod가 사용하지 않도록 하기 오랜만? 오래만에 글이다. ( 라고 맨날쓴다. ㅎ ) kubernetes에서 GPU를 사용하다 보니 문제가 몇가지 생겨서 이를 해결하는 방법을 찾아, 기록으로 남겨두고자 한다. 너무 기니깐.. 정리하면 조건 : Kubernetes에서 Container Runtime을 Docker로 사용하고, NVIDIA GPU 사용을 위해 docker의 default-runtime을 nvidia-docker로 설정한 경우. 문제 : Kubernetes에서 뜨는 Pod에서 GPU 자원을 못쓰게 하고 싶은데, docker nvidia runtime으로 인해 Container가 무조건 GPU를 보게 되는 상황. 해결 : 환경 변수로 CUDA_VISIBLE_DEVICES= 값을 줘, CUDA Library 단에서 GPU 자원을.. [Kubernetes] k3s를 이용해 multi node 쿠버네티스 클러스터 구축하기 이전 글에서는 k3s를 이용하여 쉽게 single node kubernetes cluster를 구축하는 법을 알아 보았다. ( https://blog.ggaman.com/1018 ) 이번 글에서는 k3s를 이용해서 multi node kubernetes cluster를 구축하는 법을 알아 보겠다. 즉, 컴퓨터 여러대를 묶어서 사용하겠다는것이다. 이전의 글을 보고 왔으면 크게 할 일이 없지만 몇가지 사소하게 설정이 필요한 부분이 있어서 이 글도 따로 작성하게 되었다. 이전글에도 적어 두었지만, 쿠버네티스는 master node와 worker node로 구분되고, master node가 worker node를 조작한다고 설명했다. 그렇기 때문에 실제 서비스가 돌아가는곳은 worker node이므로, mast.. [Kubernetes] k3s를 이용해 single node 쿠버네티스 클러스터 구축하기 업무 관련으로 Kubernetes를 사용하려고 준비중이다. 하지만 쿠버네티스를 "사용"하는 것과 "설치"하는것은 많은 차이가 있다. 사용하면서 알아야 할 개념이 60이라면, 설치하면서 알아야 할 개념은 80, 운영까지 포함해야 100이 된다고 생각한다. 즉, 단순히 사용만 할 것인데, 나머지 40까지의 개념을 알아야 할까? 그래서 Kubernetes 쪽 세상에서는 단순하게 사용할 수 있도록 하기 위해서 여러 쉬운 도구를 제공한다. 그 중에서 유명한게 minikube, k3d, kind, k3s 등이 있다. 4 개를 대충 사용해 봤고, 처음에는 k3d로 클러스터를 구축해 봤었다. k3d는 docker container에 k3s가 설치되어 kubernetes를 구축하는 형태이다. 그러므로 반드시 docker.. 간단한 클라우드 서버(VPS) 만들기 - Vultr - VPS 요즘에 회사에서 Kubernetes 관련 업무를 하고 있다. 실제로 내가하는건 별로 없고, 대부분 팀의 다른분들이 다 하지만, 그래도 뭔가를 좀 알아야 하니깐 집에서도 이것저것 해 보고 있다. Kubernetes를 하니깐 당연히 Cluster를 구축해 보는게 좋을것이다. GCP나 AWS에 모두 Kubernetes cluster를 제공해 주고 있으나, 이것저것 직접 해 보려고 일부러 VPS(Virtual Private Server)를 여러개 묶어서 해 보고 있다. Kubernetes를 모두 이해하는건 어려우니 지금은 k3s (https://k3s.io/) 를 이용해서 해 보고 있다. 다음 기회에 k3s에 관해서 써 볼 수 있도록 하겠다. 잡설은 그만. VPS를 제공해 주는데가 여러곳이 있는데, 이 중에서 .. 이전 1 2 3 4 5 ··· 36 다음