 일래스틱 스택 6 입문(Learning Elastic Stack 6.0) - 일래스틱서치, 로그스태시, 키바나, 엑스팩 활용 가이드
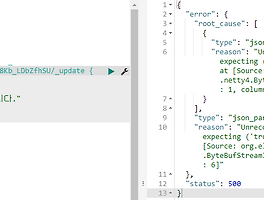
이것저것 공부하기 데이터를 많이 모아 보려고 하고 있다. 데이터를 모으는것은 그냥 모으면 되지만, 이것들을 어떻게 활용 할 것인가에 대한 고민... 데이터를 "처리"하는 부분 데이터를 "분석"하는 부분 데이터를 "활용"하는 부분 으로 나뉘어 질텐데, 우선 텍스트를 쉽게 분석? 할 수 있는 엘라스틱 스택에 대해서 공부 하기로. 읽기 우선 이 책은 초보자를 위한 책은 아님이 확실하다. 엘라스틱 서치의 많은 것을 알려 주기는 하지만, 설명이 장황하고, 구체적이다. 초보가 보기에는 정보가 너무 많아, 너무 어렵게 느껴 질 것으로 판단된다. 이 글에서는, 책의 순서가 뒤죽 박죽이 될 수도 있겠다. 02장 일래스틱서치 시작하기 ubuntu 에서 apt로 elasticsearch를 설치하면, 9200 포트에 접근이 ..
일래스틱 스택 6 입문(Learning Elastic Stack 6.0) - 일래스틱서치, 로그스태시, 키바나, 엑스팩 활용 가이드
이것저것 공부하기 데이터를 많이 모아 보려고 하고 있다. 데이터를 모으는것은 그냥 모으면 되지만, 이것들을 어떻게 활용 할 것인가에 대한 고민... 데이터를 "처리"하는 부분 데이터를 "분석"하는 부분 데이터를 "활용"하는 부분 으로 나뉘어 질텐데, 우선 텍스트를 쉽게 분석? 할 수 있는 엘라스틱 스택에 대해서 공부 하기로. 읽기 우선 이 책은 초보자를 위한 책은 아님이 확실하다. 엘라스틱 서치의 많은 것을 알려 주기는 하지만, 설명이 장황하고, 구체적이다. 초보가 보기에는 정보가 너무 많아, 너무 어렵게 느껴 질 것으로 판단된다. 이 글에서는, 책의 순서가 뒤죽 박죽이 될 수도 있겠다. 02장 일래스틱서치 시작하기 ubuntu 에서 apt로 elasticsearch를 설치하면, 9200 포트에 접근이 ..



